FD001 vs FD002
Can two similar datasets produce completely different predictive feasibility outcomes?
Classification Summary
FD001 → GO
FD002 → NO-GO
Key Insight
Signal structure matters more than dataset category.
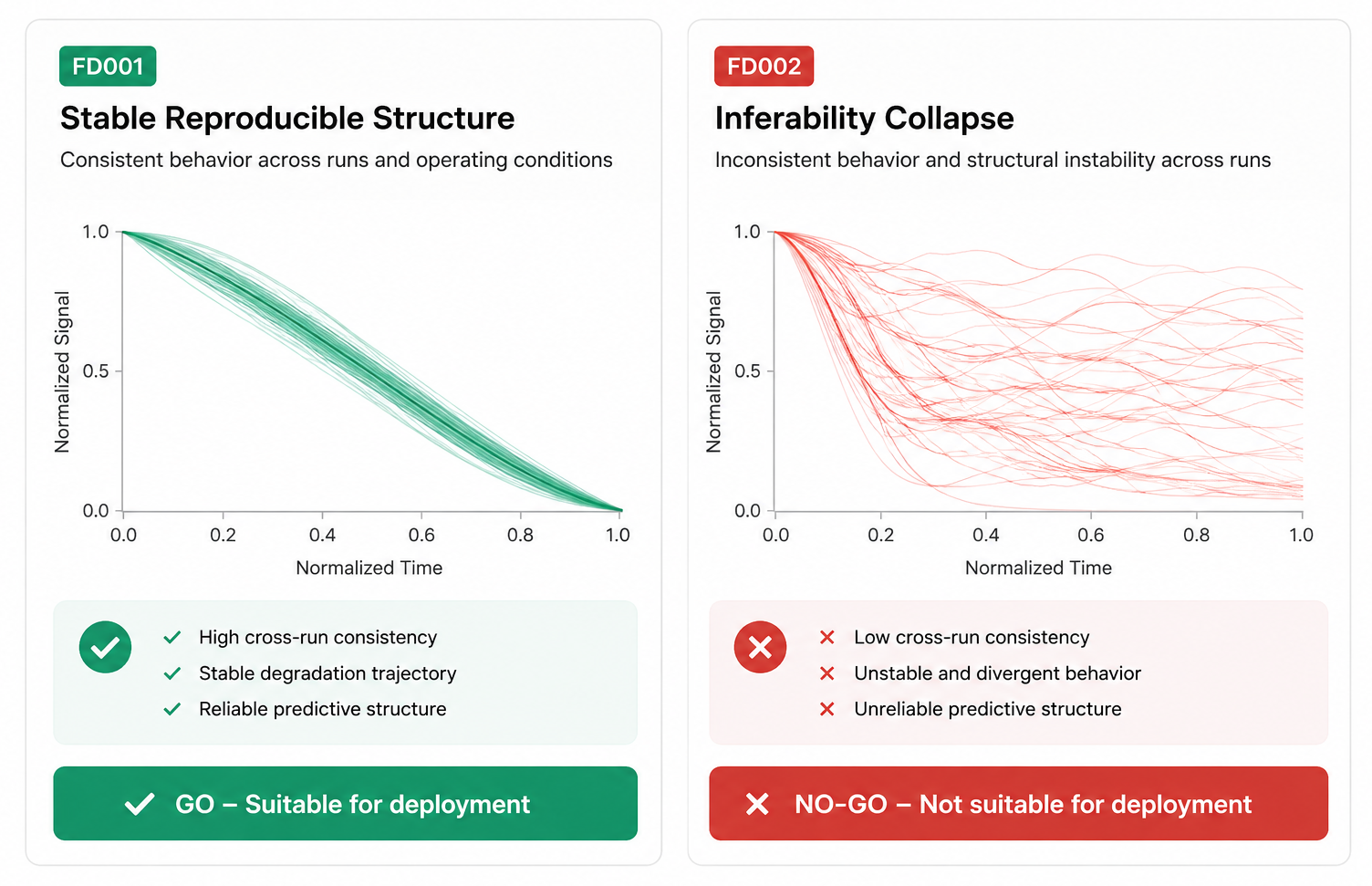
Figure 1 — FD001 versus FD002
Comparison of predictive feasibility behavior across the NASA C-MAPSS FD001 and FD002 datasets.
Why This Matters
Many predictive AI projects begin with the assumption that prediction is possible simply because data exists.
This case demonstrates that:
• Similar datasets can produce fundamentally different predictive outcomes.
• Model complexity cannot compensate for missing reproducible structure.
• Predictive feasibility should be evaluated before model development begins.
The limitation is often not the model.
The limitation already exists within the signal.
Key Takeaway
Two datasets.
One benchmark family.
Completely different predictive feasibility outcomes.
The difference is not model choice.
The difference is signal structure.